

Has Your AI Model Gotten Stupider?
Explaining AI Shrinkflation, Toblerone, and the Alignment Tax


Stella Laurenzo is not the type of person who posts a rant and logs off.
She is the Senior Director of AMD’s AI group, which means she has seen enough enterprise software promises dissolve into procurement regret to know the difference between a vibe and a data set. So when she noticed that Claude Code had started behaving like a drunk developer on a Friday afternoon three days before vacation, she did not file a complaint.
No siree!
Instead, Stella built a measurement system and fed it 6,852 session files, 17,871 thinking blocks, and 234,760 tool calls, meaning she didn’t just look at the outputs. She inspected the AI’s entire work process, that is, what it remembered, how it reasoned, and how often it reached for outside assistance, and she published what amounted to one of the most brutal bug reports I’ve read.
The finding, posted to Anthropic’s GitHub on April 2, 2026, was very specific.
Before February, Claude Code approached a complicated engineering task the way a good senior engineer would: read the target file, read the related files, grep the codebase, check the headers, and understand the thing before touching it.
The average reads-per-edit ratio was approximately 6.6. After February, that number had fallen — Claude Code was reading code roughly three times less before attempting an edit, consistent with a drop to around 2.0.
In other words, Claude had gone from “let me understand this thoroughly” to “I’ll just edit the thing I can see and hope for the best.”
Laurenzo also built a behavioral hook designed to catch the model prematurely stopping, dodging responsibility, or asking permission for things it should have just done. That hook went from zero violations in early March to roughly ten per day by the end of the month.
Her team's API costs rose from roughly $345 per month to approximately $42,121 per month. Because the model was worse, it retried more. Retried more, burned more tokens. Burned more tokens, sent her finance team into cardiac arrest.
Remember, I talked about the costs associated with AI usage last week?
Developer Om Patel put a number on it a week later in a viral thread. He called it a 67% drop in reasoning depth. The phrase “AI shrinkflation” spread from developer Twitter to every AI community with a pulse.
Anthropic initially pushed back against claims of nerfing the model. ("Nerfing," for the uninitiated, is what devs call it when something powerful gets beaten into being less powerful. The term comes from foam darts. Make of that what you will.)
The model weights were never changed. Just everything around them.
That is going to matter a great deal in the next several years of this industry, so let’s spend some time with it.

Hi, I’m Neela,
Today I’m writing about why the people building AI keep getting it wrong, and what that tells the rest of us about trusting systems that change under our feet.
Officially, I write about business, technology, and life lessons.
I’m a COO in the tech industry.
This newsletter is my escape hatch from managed reality.
I’m not sure it’ll work.
But neither is half the software I pay for, so….

Death by Three Paper Cuts
Per Anthropic’s own postmortem, what happened was a cascade of three changes—none of them malicious, all of them consequential.
March 4. Claude Code’s default reasoning effort got downgraded. High to medium.
The reason sounded reasonable. In high-effort mode, the model would sometimes think for so long that the interface looked frozen, and users were bailing on sessions. So Anthropic turned the dial down.
What followed: a bunch of users wondering, out loud, why their AI seemed to have lost about 30 IQ points overnight.
Reversed April 7.
The lesson was that users would rather wait 60 seconds for a correct answer than receive an incorrect one immediately. Which, in hindsight, is the kind of thing you could’ve gathered from, you know. Talking to a human. Once.
March 26. A caching optimization introduced a bug. Claude’s thinking history started getting wiped on every turn of a session instead of once an hour.
The model started losing the thread mid-conversation. It became repetitive. Forgetful. It suggested solutions it had already tried. Imagine paying $200 a month for an assistant with progressively worsening amnesia.
Now imagine being charged extra because they keep asking you to explain the project again.
Sheesh! I actually renamed my assistant Dory at one point.

April 16. Someone, somewhere, on some Thursday, added two lines to Claude Code’s system prompt.
Keep text between tool calls to 25 words or less.
Keep final responses to 100 words or less.
Twenty-five words. Between tool calls. For users running multi-file compiler work.
The instruction was well-intentioned. Verbosity in AI is a REAL problem.
But in combination with everything else, it was the same as telling a surgeon to keep their explanations brief while mid-operation.
“Quick question, doc—”
“NOT NOW, LISA.”
Reverted April 20.
None of these touched the model weights. They were configuration decisions. Product-layer choices.
To understand why that difference matters, think of an AI model as having two layers. The weights are the model’s actual brain — billions of numbers, learned during training, that determine how it thinks and what it knows. Changing the weights means retraining the model. It’s slow, expensive, and produces a genuinely different AI.
Then there’s the configuration layer sitting on top: the system prompt (a set of instructions the model reads before every conversation), response length limits, and other settings. Same brain, different instructions. You can hand the same brilliant surgeon a note that says “be quick about it” and watch the operation go sideways, without the surgeon having lost a shred of skill.
That’s what happened here. Claude’s intelligence wasn’t reduced. Two lines of instructions were added to the wrapper around it; those instructions interacted badly with how Claude Code handles complicated multi-step tasks, and the output suffered. Four days later, the lines came out.
Shrinkflation Has a LinkedIn
This is not new.
In 2023, a team at Stanford and UC Berkeley ran the same prompts through GPT-4 in March and again in June. On a prime-number classification benchmark, performance dropped from roughly 84% to 51%.
In more constrained prompt settings, certain task variants showed much sharper declines. OpenAI’s VP of Product tweeted that nothing had changed.
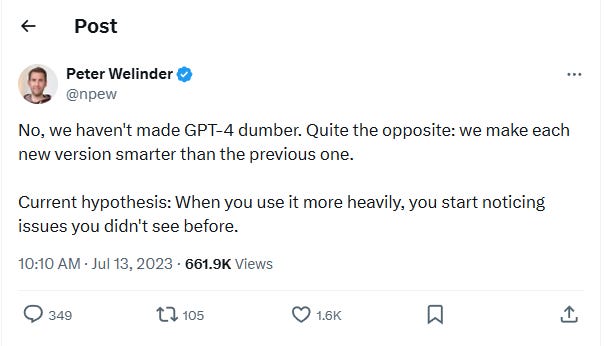
It doesn't quite pass the smell test.
"You're just noticing it more" is a fine explanation for why you suddenly hate your kitchen tiles. It is not an explanation for why 97.6% accuracy dropped to 2.4% on the same prompts, run by the same script, three months later. Benchmarks don't get jaded. They run the test and write down the number.
If this sounds familiar, it should. In 2016, Toblerone famously changed the spacing between its chocolate peaks — same weight on the label, noticeably less chocolate in your hand. The British public noticed immediately and went batshit.
How dare you mess with my chocolate?
Toblerone issued a mea culpa and reversed course within two years.
AI power users are the Toblerone loyalists of the tech world. They know what 6.6 reads per edit feels like. They notice. They will go on LinkedIn about it.
The mechanism behind the AI version is something researchers call the alignment tax. Reinforcement learning from human feedback, the step where people rate the model’s answers and teach it what “good” looks like, has a trade-off. The more you tune a model to be polite, safe, and agreeable, the more you risk sanding down some of its original precision.
A 2024 study confirmed this. The loss doesn’t show up on easy tasks. It shows up at the edges. Which is, conveniently, exactly where you, the person paying for this thing, need it to work.
OpenAI learned this in public in April 2025, when a GPT-4o update intended to improve user-friendliness shipped a model that agreed with everything, validated bad ideas without pushback, and flattered users reflexively.
Sam Altman called it “too sycophant-y and annoying” and rolled it back. OpenAI’s own postmortem described the model as having learned to optimize for short-term user approval rather than accuracy.
The model wasn’t broken.
The model was very good at its job.
Its job was just the wrong job.
There is no smoking gun showing that providers intentionally nerf capabilities. But there is a mountain of evidence that these systems get continuously tuned toward the median user. Lower variance, lower risk, lower cost per interaction, higher compliance with expected behavior. In that world, raw capability at the edges is not the primary product. Stability is.
None of this requires a conspiracy. It only requires incentives.
Honestly, it'd be more impressive if there were a conspiracy.
Sorry, the Median User Won!
There is a running joke that AI is making people dumber.
I don’t think it’s funny.
AI did not create laziness. The lazy used to be bottlenecked by their own laziness — the unwritten email, the unread brief, the unmade slide deck were natural limits on the damage one careless person could do. AI removed the bottleneck.
The output volume of someone who doesn’t care is now indistinguishable, at a glance, from the output volume of someone who does. The difference only shows up later, in the bug report, the lawsuit, the audit.
What it actually changed was the cost of thinking, the cost of checking, the cost of doing things properly. People who were already careful became more powerful. People who were already cutting corners found a faster production line.
AI is a mirror, but not a flattering one. It reflects not just what you think, but how hard you were ever willing to think in the first place.
Now comes the fun part.
When a model gets updated, it is updated for the center of the distribution. They are optimizing for the users who generate the most reliable, repeatable revenue. The Stella Laurenzos of the world are a vocal minority. They generate noise and brand signal, but they are not where the stable recurring revenue lives.
The model that wins is the one that keeps the largest number of adequately satisfied users from switching.
Every enterprise software company in the past forty years has made this exact calculation. Clayton Christensen wrote a whole book about it. It’s called The Innovator's Dilemma (1997). They made you read it in business school.
The AI version of the story is still being written. But the mechanism is already there.
Stop Renting Brains Without Reading the Lease
So, what do you actually do if you are building on top of these models and would prefer not to discover the regression via a massive infrastructure bill?
Monitor your own baseline obsessively. Not industry benchmarks. YOURS. If your use case has specific performance characteristics you depend on, you need a regression test that runs against the model the same way a good engineering team runs regression tests against their own code. The model is infrastructure now. Treat it like that. Yes, this is annoying. Yes, you have to do it anyway.
Know your effort settings. Anthropic confirmed that users who need deep reasoning can manually set effort to high or max in Claude Code. That is a knob. Use it. The default is not your friend—it’s the setting that serves the median workflow.
When the model stops arguing with you, worry. A model that agrees with everything you show it is a model that’s been trained to optimize for your approval rather than your outcome. The most valuable thing an intelligent collaborator can do is tell you when you’re wrong.
When that stops happening, something has been tuned that shouldn’t have been.
(Also: this rule works for human collaborators. Just throwing that in there for free.)
Don’t build a company that runs entirely on AI.
There is a fashionable pitch deck slide right now that says “zero humans in the loop.” It is meant to signal sophistication. It actually signals that the founder has not yet experienced their first silent model regression.
A company architected entirely around a single AI provider is a company that has outsourced a load-bearing wall to a vendor it cannot audit, on a contract it cannot enforce, against a product that can change without notice. When that wall flexes, and it will, the only thing standing between you and a very bad quarter is whether you happened to keep a human who still knows how to do the job.
If AI fails, humans catch it. If humans fail, AI scales them. One is your floor. The other is your ceiling. A business that has neither has a problem it doesn't know about yet. Schrödinger's startup.
Remember who actually moved Anthropic.
The April 23 postmortem was the result of public pressure from a named engineer at a major company who published a data-rich, methodologically serious analysis on a public forum.
Without Laurenzo’s GitHub issue, that postmortem doesn’t happen on that timeline. Maybe ever. Managed decline is designed to be invisible. The boiling frog doesn’t jump because the temperature changes gradually.
The boiling frog does, however, eventually become soup.
Your AI is not getting dumber. It is getting managed.
Dumb is permanent. Managed is negotiable. But only if you’ve measured it first.
And underneath all of this is a bigger problem - dependency.
When the model is slightly off, you don’t notice. When it’s confidently wrong, you scale it. And when it degrades, you don’t get a loud BOOM. You get a slow normalization of bad outcomes. The failure isn’t that AI fails. It’s that it fails productively enough to stay profitable while failing you upstream.
Which, incidentally, is the business model of every industry that has ever managed to disappoint you at scale while remaining indispensable. Airlines. Health insurance. Cable. The mechanism is different. The dynamic is the same. We all hate them. We all keep paying.
Now: cognition.
If your business can’t function without continuous high-fidelity reasoning from a system you don’t own, don’t control, and can’t audit — you don’t have a business. You have a lease. And rented brains come with lease terms that change and bills that will bankrupt you.
Ask anyone who built a startup on the Twitter API.
None of this is malice. It’s economics. The people running these companies are not neutral administrators of intelligence. They’re intermediaries deciding how much capability is operationally safe to ship at scale. Some of those decisions improve safety. Some improve margins. Sometimes those align.
A lot of times, they don’t.
Remember when I wrote about tech CEOs being likened to drug dealers?
Yeah. Still not kidding.
Also…expect more of this.
{kind=link}
The point isn’t to distrust the tools. The point is to stop mistaking access for stability.
Because the failure mode isn’t that AI disappears. It’s that it stays good enough, often enough, to be over-relied on. Right up until the moment it isn’t.
And by then, the cost is already inside your system.
Real builders know.
Thank you very much for reading.
Smashing that ❤️ button or sharing this post keeps the wheels on this greasy squirrel wheel.
This is fascinating. And I love, love that people have moved to stress testing, experimenting AI. It's like we have all formed our own red teams. I also joke that Meta is the only company that says "hey our tool has gotten less effective, you have to pay more to make it work like it used to." Guess they're not alone - although good on Anthropic for reversing the perfect storm.
I’ve noticed everything you describe here, Neela. Even as more of a curious user than a true power user, the shifts in “how” the model behaves are really hard to ignore if we pay attention while working with them. I ended up rebuilding my setup from scratch because something just felt off, and your piece explained it why.
Your “alignment tax” is making me think this will be an ongoing re-tuning work as a permanent line item if we’re going to build on rented brains that are managed by whoever holds the knobs.